
Discover NeuroMark: From Raw Data to Refined Insights.
Achieve complete traceability, unparalleled control, and seamless integration with your existing systems.
Your Document-to-Data Journey
Documents arrive at NeuroMark in a way that suits your operations — be it via email, scan, API, or direct integration into your existing systems. No fiddly conversions. No manual filing. The document simply lands in the system, and processing kicks off automatically.
NeuroMark doesn't just scan documents — it truly understands them. A Vision Language Model (VLM) meticulously analyses layout, context, and the meaning of your content. This ensures reliable data extraction, even from poor quality scans, handwritten notes, or documents with inconsistent layouts.
Reads characters — oblivious to their meaning. It often stumbles or delivers patchy results with poor quality, handwriting, or varied layouts.
Understands the document's context. It smartly recognises that "Policy No." and "Policy Number" refer to the same field — irrespective of format, quality, or language.
NeuroMark extracts all your specified fields and, in parallel, generates a comprehensive audit trail. For each piece of data, the system shows precisely which page, section, and reasoning led to its identification. Your team gets to see not just the result, but the entire journey behind it.
The extracted data is delivered as structured JSON directly to your chosen system — whether it's your CRM software, document management system, or straight into a database. NeuroMark slots seamlessly into your existing workflow; no new interfaces for your team to get their heads around.
Every correction your team makes to the audit trail is intelligently incorporated to refine the document profile. NeuroMark smartly distinguishes between genuine corrections and mere 'noise.' The upshot: a system that grows more accurate with each iteration, all without your IT team needing to bother with manual model maintenance.
How NeuroMark logs corrections and audit trails →New Document Types – Ready in Minutes, Not Weeks
"Our documents are unique." We hear it all the time. And it's true. That's why with NeuroMark, you simply describe a new document type in plain English – just as you would brief a new team member. The system then intelligently suggests fields, validation rules, and data types. You simply review, tweak, and you're good to go. New document types are up and running in minutes – not weeks.
DKG Immobilien Dresden: Full document profile for property due diligence configured in under an hour — including Land Registry extracts, Energy Performance Certificates, and tenancy agreements.
→ Case Study: DKG Immobilien Dresden
How NeuroMark Gets Quantifiably Better
Most IDP systems claim to "learn with AI". What they actually mean is periodic retraining with fresh examples (slow, costly) or fiddly manual prompt adjustments behind the scenes (simply not scalable).
NeuroMark Evolution stands apart:
Diagnosis-Led
The system analyses error sources and reasoning paths to determine precisely what kind of adjustment is required.
Prompt & Schema Optimisation
Changes take effect instantly, no need for time-consuming model retraining. What used to take weeks now takes mere minutes.
Empirically Proven
Every proposed enhancement undergoes rigorous testing before being implemented. No shooting in the dark.
Complete Auditability
A full audit trail for every single attempt: What was tried? What hit the mark? What didn't quite work? And crucially, why?
Evolution operates on accumulated feedback – kicking in once a defined threshold is met, rather than after every single tweak.
For the full lowdown on our audit trail architecture →Seamless Integration, No IT Project Required
Upload and email forwarding are operational from day one. For more advanced integrations: REST API, DMS connectors, scanner pipelines.
NeuroMark slots right into your existing infrastructure. There's no need to overhaul your current workflows.
No vendor lock-in. Structured JSON output, compatible with all standard systems.
Scale with Hardware, Not Headcount
Whether you're processing a hundred or a hundred thousand documents monthly, your scaling comes from GPU capacity, not from adding more staff.
The more documents you handle, the lower your cost per document becomes – all without needing extra personnel.
35+ Ready-to-Use Document Profiles
Designed for common German insurance and financial documents, including Home Contents, Car Insurance, Income Protection, State Pension, Public Liability, Land Registry Records, ID Cards, Driving Licences, and more. Many of our customers are up and running without needing to create a single new profile.
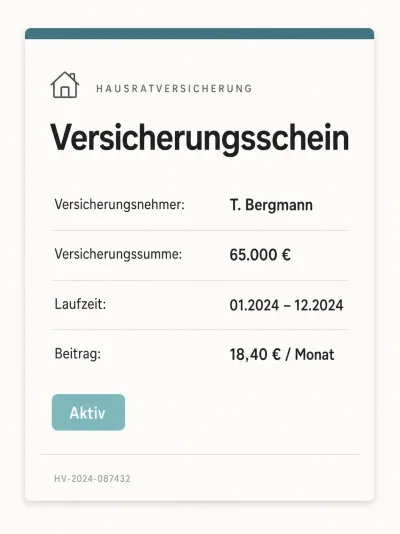 Home Contents
Home Contents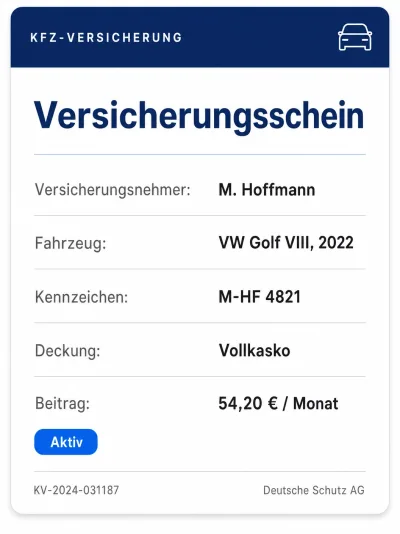 Car Insurance
Car Insurance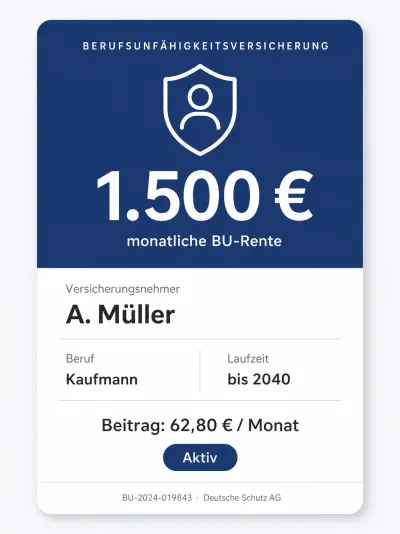 Income Protection
Income Protection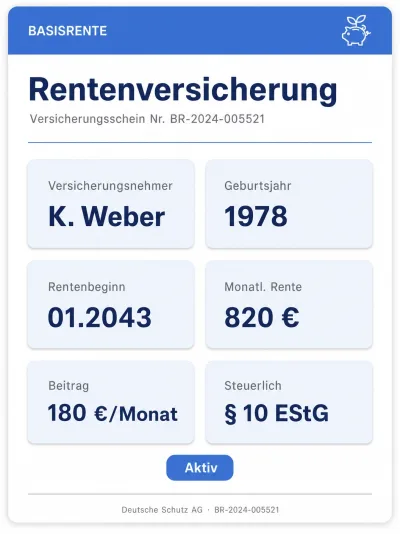 State Pension
State Pension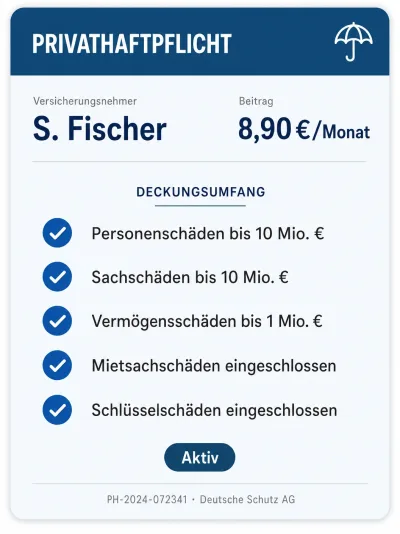 Public Liability
Public Liability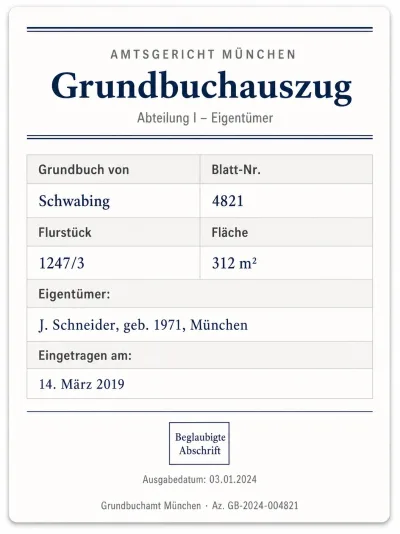 Land Registry Record
Land Registry Record Driving Licence
Driving Licence ID Card
ID Card Car Insurance – Page 2
Car Insurance – Page 2